

I’m starting this NVIDIA Academy series, with a pursuit of deeper understanding of networking commodity within data center. These blog series will be entirely written by me, with little to no help from AI. However, I will be using AI as my learning companion. I will be primarily focusing on below topics within NVIDIA Academy:
- InfiniBand Essentials / Network Admin
- MLXlink & MLXcables Debug Tools
- AI Infrastructure and Operations Fundamentals
Why I’m doing these courses? What is my end goal? Let me explain this in few sentences and then I will start sharing notes from the above trainings. Few weeks ago, I have completed IPC/WHMA-A-620 Requirements and Acceptance for Cable/Wire Harness Assemblies Specialist certification. By completing this training, I understood the physical layer better than 90% of quality engineers working in networking commodity. I now know what constitutes a good crimp, a proper solder joint and a reliable harness. This training gave me good understanding of physical construction, quality and acceptance of cable assemblies.
However, I want to build a unique and powerful skill set: the ability to understand a high speed interconnect from the microscopic solder joint (IPC) all the way up to its role in training LLM’s. The InfiniBand Essentials / Network Admin will teach me the “system” that relies on those perfect cable assemblies. With MLXlink & MLXCables debug tools, I will be able to connect a physical manufacturing defect (which I know how to spot from IPC) to a specific digital error code or sensor reading (which I’ll learn in this course). I feel this ability to bridge the physical and digital worlds is rare and is extremely valuable. I will continue to pursue this path outside of NVIDIA Academy (but more on it later).
InfiniBand Essentials / Network Admin
What is InfiniBand? A simple google search tells me “InfiniBand is a high-speed computer networking standard for high-performance computing and data centers, known for its very high throughput and low latency.” We all know ethernet, which is the standard for most office and home networks. But this was designed from the ground up for the most demanding computing tasks. Infiniband has several components. It is designed as below:

I have asked AI to explain the necessity of each component in a digestible manner and here is what it said:
Hosts/Servers : These are the physical servers (e.g., NVIDIA DGX or GB200/300) that hold the GPU’s doing the actual thinking. Each AI Model is “data parallel” or “model parallel” meaning its split across thousands of these GPU’s. Each host runs a small piece of the job and then must immediately share its results with every other host/server

Host Channel Adapter: This means when the GPU on Host “A” finishes calculation, the HCA grabs that result directly from GPU’s memory and places it directly into the memory of the GPU’s on Hosts B,C,D etc. These HCA’s (like NVIDIA ConnectX-7 Adapter) provides Remote Direct Memory Access (RDMA).

Subnet Manager: This is a management software (often running on a switch or a dedicated server/host). It builds and maintains the network map. When we add new rack of servers to the cluster, this subnet manager automatically discovers them, assigns them an address and recalculates the fastest possible routes from every server to every other server. If a cable or switch fails, the SM instantly reroutes the traffic around the damage. So this subnet manager plays a key role in maintaining a resilient supercomputer.

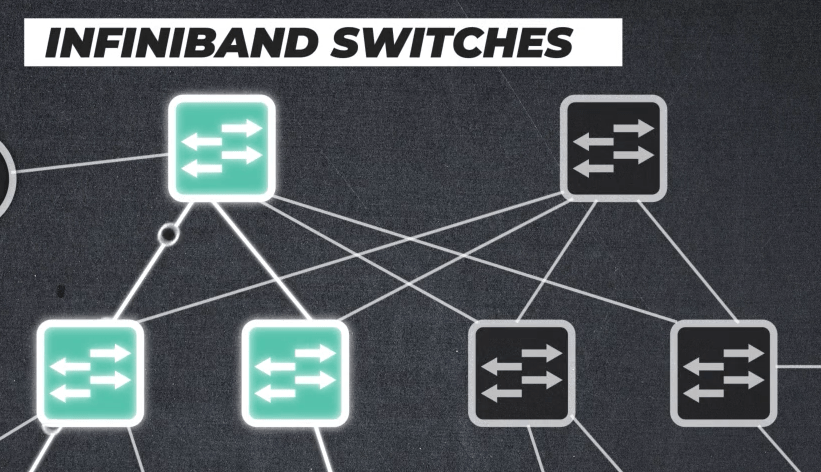
Switch: There are multiple switches in InfiniBand clusters. Its job is to handle the simultaneous, massive data sharing operations from all the servers/hosts.
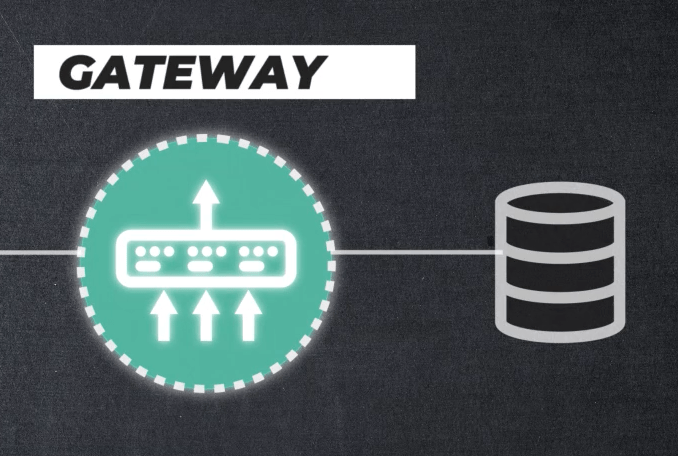
Gateway: The InfiniBand network is very fast, but its separate from the regular office network (ethernet). How do we get out training dataset in and our final mode out? The gateway is our answer. This acts like a bridge between the InfiniBand fabric (AI cluster) and the ethernet network (corporate network). It is a secure “loading dock” for moving data in and out of the high performance zone.
Router: Lets say if the AI job is enormous, it might several different clusters similar to this one. The router connects these massive subnets together. It lets build the “hyperscale” system allowing AI models to scale across tens, thousands of GPU’s in different halls, rooms, all while making them behave like one single, giant InfiniBand fabric

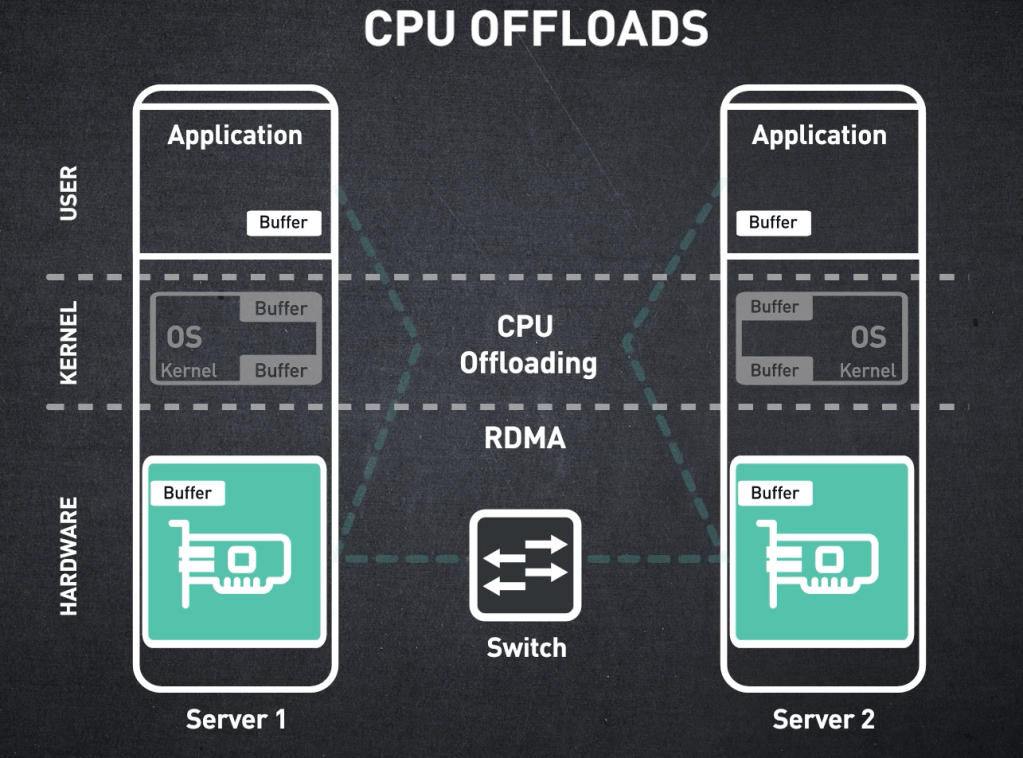
Now we will explore the concept of CPU Offloads: CPU offload is the act of moving all the repetitive, low level networking tasks off the main CPU and onto the specialized processor on the Host channel Adapter (HCA). To understand this concept, Lets use an analogy:
I type a prompt into an AI model. The model is so huge its spread across 100s of different servers/hosts, each with lets say 8 GPU’s.
Here are the process steps without CPU Offload:
- Me: “Give me a picture of a blue horse.”
- GPU 1 : Finishes its part (e.g., “calculating horse-shape”). It shouts, “Done! This needs to go to GPU 2!”
- CPU : Stops prepping the next step. It runs over, takes the “horse-shape” data from GPU 1, carefully puts it in a delivery box (formats it into network packets), runs it to the loading dock (the NIC), and hands it to the delivery driver.
This process is a massive waste of the Master Chef’s (CPU’s) time. Your $50,000 GPUs are now sitting idle, waiting for the CPU to finish playing “delivery driver” before it can give them their next cooking instruction. Instead, here is what happens with InfiniBand CPU offload:
- Me: “Give me a picture of a blue horse.”
- CPU: Gives the first instruction to the GPUs and the HCAs: “GPUs, when you finish your part, give your result directly to the Delivery Robot (HCA). Robot, your job is to take whatever GPU 1 gives you and put it directly into GPU 2’s workstation.”
- GPU 1: Finishes “calculating horse-shape.”
- The “Offload” Happens:
- The HCA (Robot) directly pulls the data from GPU 1’s memory. This is called GPUDirect RDMA.
- The HCA handles all the boxing (packet formatting) and error-checking on its own processor.
- It sends the data across the network (via the Switch).
- The HCA on Server 2 receives the data and places it directly into GPU 2’s memory.
During this entire process, the CPU was 100% free and was already busy prepping the next step of my AI prompt.
Before we move further, I want to re-check on where I’m going with these concepts. InfiniBand’s advanced features like ultra low latency RDMA, CPU offloading, load balancing, all depend on the physical perfection of the cables and connectors for high speed IO applications. So for a quality engineer working in this field, its extremely important to understand that cables and interconnect quality and reliability is high class to ensure low latency and signal integrity is maintained. Hence the physical layer (cables, transceivers, connectors) is the only one guaranteeing the effective signal integrity in InfiniBand architecture layer.
